Redis是一个键值对数据库,数据库中的键值对由字典dict保存,每个数据库都有一个对应的字典,这个字典被称之为键空间(key space)。
字典dict涉及的数据类型有:
- dictType
- dictEntry
- dictht
- dict
- dictIterator
- dictScanFunction
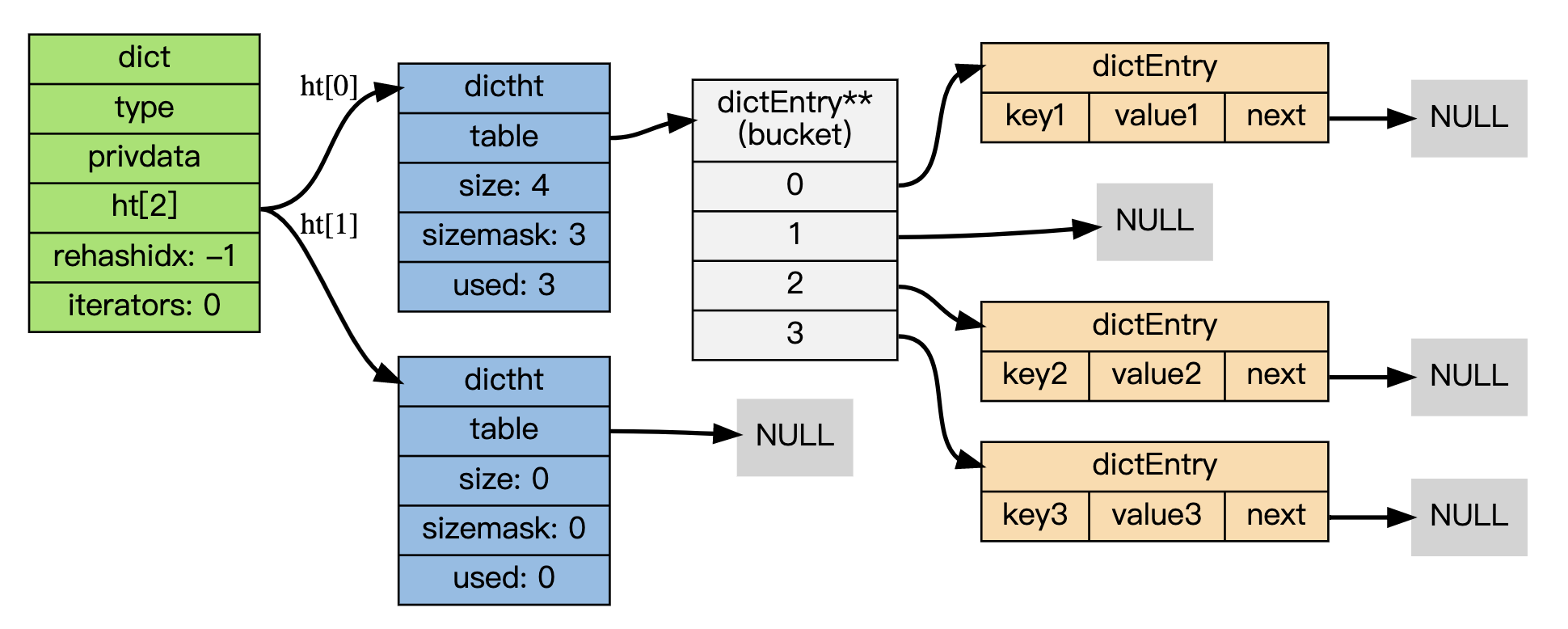
从上图我们可以看出dictEntry,dictht,dict之间的关系,字典dict具有两个哈希表dictht(之所以采用两个哈希表,是为了渐进式哈希扩缩容使用),dictEntry对应的就是哈希表中的具体元素,这里采用了开链法来解决哈希冲突。
dictIterator是字典迭代器,有两种模式:安全模式和非安全模式。
dictType通过提供一组自定义函数来处理dict字典中保存的不同类型数据,类似于Java中的泛型机制,提供的方法有:
- hashFunction(*key)
- keyDup(*privdata, *key)
- valDup(*privdata, *obj)
- keyCompare(*privdata, *key1, *key2)
- keyDestructor(*privdata, *key)
- valDestructor(*privdata, *obj)
dictEntry
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;dictEntry有三个字段:
- key: 键对应的指针
- v: 值(浮点型、无符号长整型、有符号长整型、指针)
- next: next指针
dictEntry涉及的宏或方法有:
- dictFreeVal: 调用dictType的valDesctructor()方法释放值空间
- dictSetVal: 调用dictType的valDup()方法设置值
- dictSetSignedIntegerVal: 设置有符号长整型值
- dictSetUnsignedIntegerVal: 设置无符号长整型值
- dictSetDoubleVal: 设置浮点型值
- dictFreeKey: 调用dictType的keyDestructor()方法释放健空间
- dictSetKey: 调用dictType的keyDup()方法设置键
- dictCompareKeys: 两个键比较大小
dictIterator
字典迭代器有两种模式:安全模式和非安全模式
安全模式下,在遍历的过程中我们可以调用dictAdd(),dictDelete()等方法;非安全模式下,我们只能使用dictNext()方法进行遍历。
字典迭代器对应的方法:
- dictFingerprint
- dictGetIterator
- dictGetSafeIterator
- dictNext
- dictReleaseIterator
字典指纹
我们在创建非安全的字典迭代器的时候,会给字典生成一个指纹,这个指纹由dictht.table, dictht.size, dictht.used三个字段进行一系列异或操作生成。
如果在遍历过程中,字典有任何操作导致这三个字段改变的话,字典的指纹也会发生改变。在迭代完成之后,会检查指纹是否一致,如果指纹不一致,说明发生了毁坏性操作,进程会直接退出!
迭代器创建&销毁
直接看代码吧:dictIterator *dictGetIterator(dict *d)
{
dictIterator *iter = zmalloc(sizeof(*iter));
iter->d = d;
iter->table = 0;
iter->index = -1;
iter->safe = 0;
iter->entry = NULL;
iter->nextEntry = NULL;
return iter;
}
dictIterator *dictGetSafeIterator(dict *d) {
dictIterator *i = dictGetIterator(d);
i->safe = 1;
return i;
}
void dictReleaseIterator(dictIterator *iter)
{
if (!(iter->index == -1 && iter->table == 0)) {
if (iter->safe) //安全模式迭代器要处理字典的iterators字段
iter->d->iterators--;
else //非安全模式迭代器要校验字典指纹是否相等
assert(iter->fingerprint == dictFingerprint(iter->d));
}
zfree(iter);
}
遍历过程
整个遍历过程大致如下:
- 初始化工作:iterators++或者保存字典指纹
- 从第一个dictht开始遍历
- 遍历第一个槽位,会依次遍历槽位链上的所有元素
- 遍历剩下的所有槽位
- 如果字典正在进行重哈希,那么继续遍历下一个dictht,否则遍历结束
dictEntry *dictNext(dictIterator *iter)
{
while (1) {
if (iter->entry == NULL) {
dictht *ht = &iter->d->ht[iter->table];
if (iter->index == -1 && iter->table == 0) {
//迭代器第一次遍历时,要处理字典iterators字段或者计算字典指纹
if (iter->safe)
iter->d->iterators++;
else
iter->fingerprint = dictFingerprint(iter->d);
}
iter->index++;
if (iter->index >= (long) ht->size) {
//如果字典正在进行重哈希的话,迭代完第一个dictht后,还要继续迭代下一个dictht
if (dictIsRehashing(iter->d) && iter->table == 0) {
iter->table++;
iter->index = 0;
ht = &iter->d->ht[1];
} else {
break;
}
}
iter->entry = ht->table[iter->index];
} else {
iter->entry = iter->nextEntry;
}
if (iter->entry) {
/* We need to save the 'next' here, the iterator user
* may delete the entry we are returning. */
iter->nextEntry = iter->entry->next;
return iter->entry;
}
}
return NULL;
}问题:
dict.iterators字段的作用?如果iteratos字段大于0,表明字典当前存在安全模式迭代器,它会阻止字典进行重哈希!
问题: 如果在遍历过程中,迭代器的
entry和nextEntry都被删除的话,会是什么情况?